
Already familiar with the SDK? You can reuse patterns from the SDK Quickstart and Tracing Quickstart.
Steps
Setup accounts
Create a Scorecard account, then set your API key as an environment variable.
Install SDK (and OpenAI optionally)
Install the Scorecard SDK. Optionally add OpenAI if you want a realistic generator.
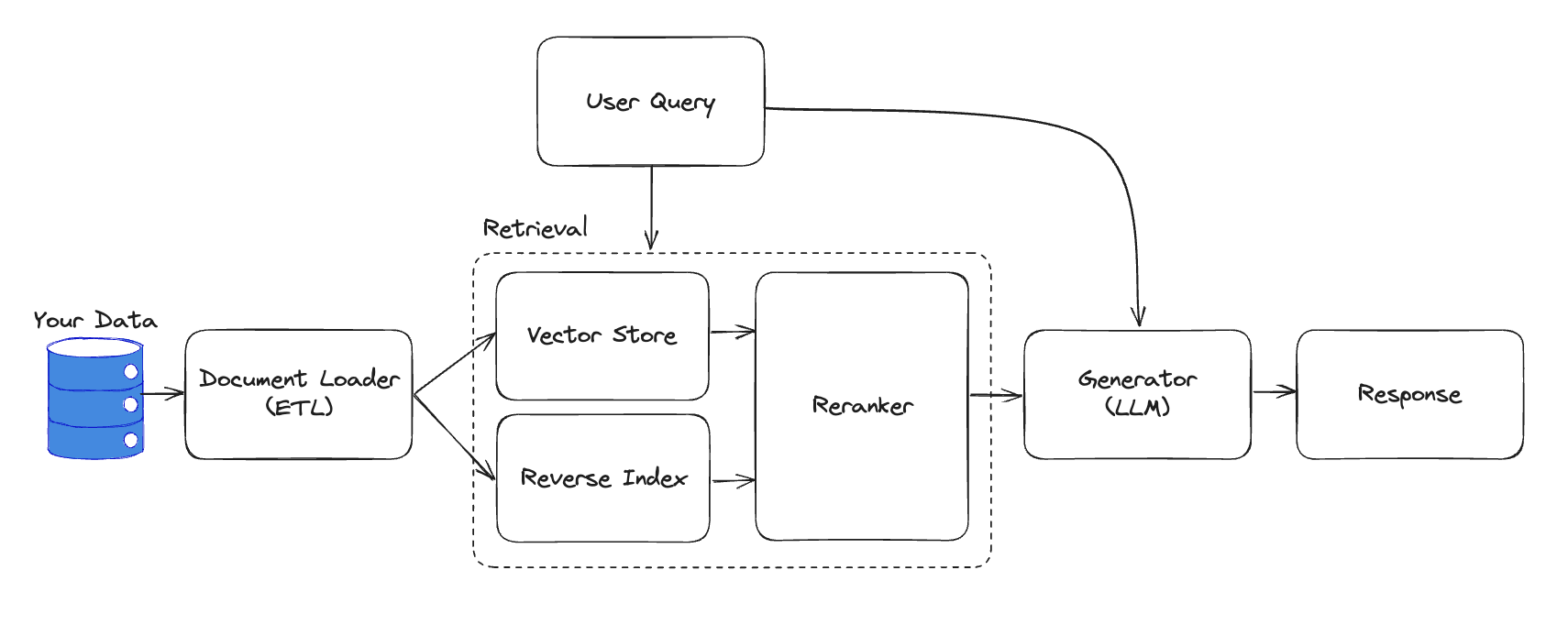
Create a minimal RAG system
We’ll evaluate a simple function that takes a query and retrievedContext and produces an answer. This mirrors a typical RAG loop where retrieval is done upstream and passed to the generator.
- Python
- JavaScript
Create RAG testcases
Each testcase contains the user
query, the retrievedContext you expect to be used, and the idealAnswer for judging correctness.Create AI judge metrics
Define two metrics: one for context‑use (boolean) and one for answer correctness (1–5). These use Jinja placeholders to reference testcase inputs and system outputs.
Run and evaluate
Use the helper to execute your RAG function across testcases and record scores in Scorecard.
Retrieval‑only and end‑to‑end tests
Beyond the simple loop above, you may separately evaluate retrieval quality (precision/recall/F1, MRR, NDCG) and combine with generation for end‑to‑end scoring.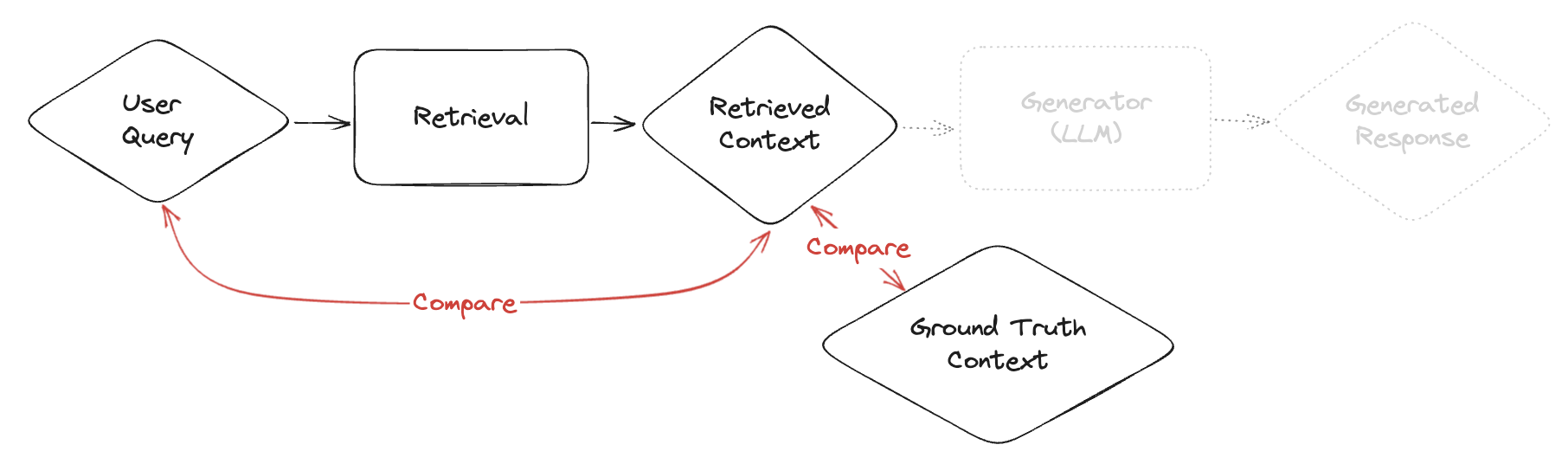
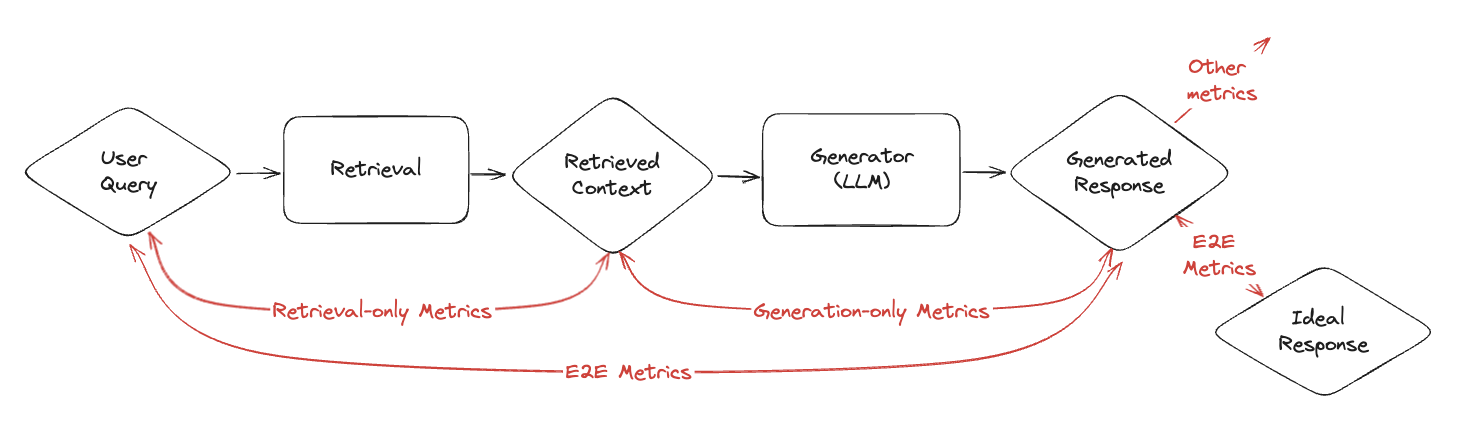
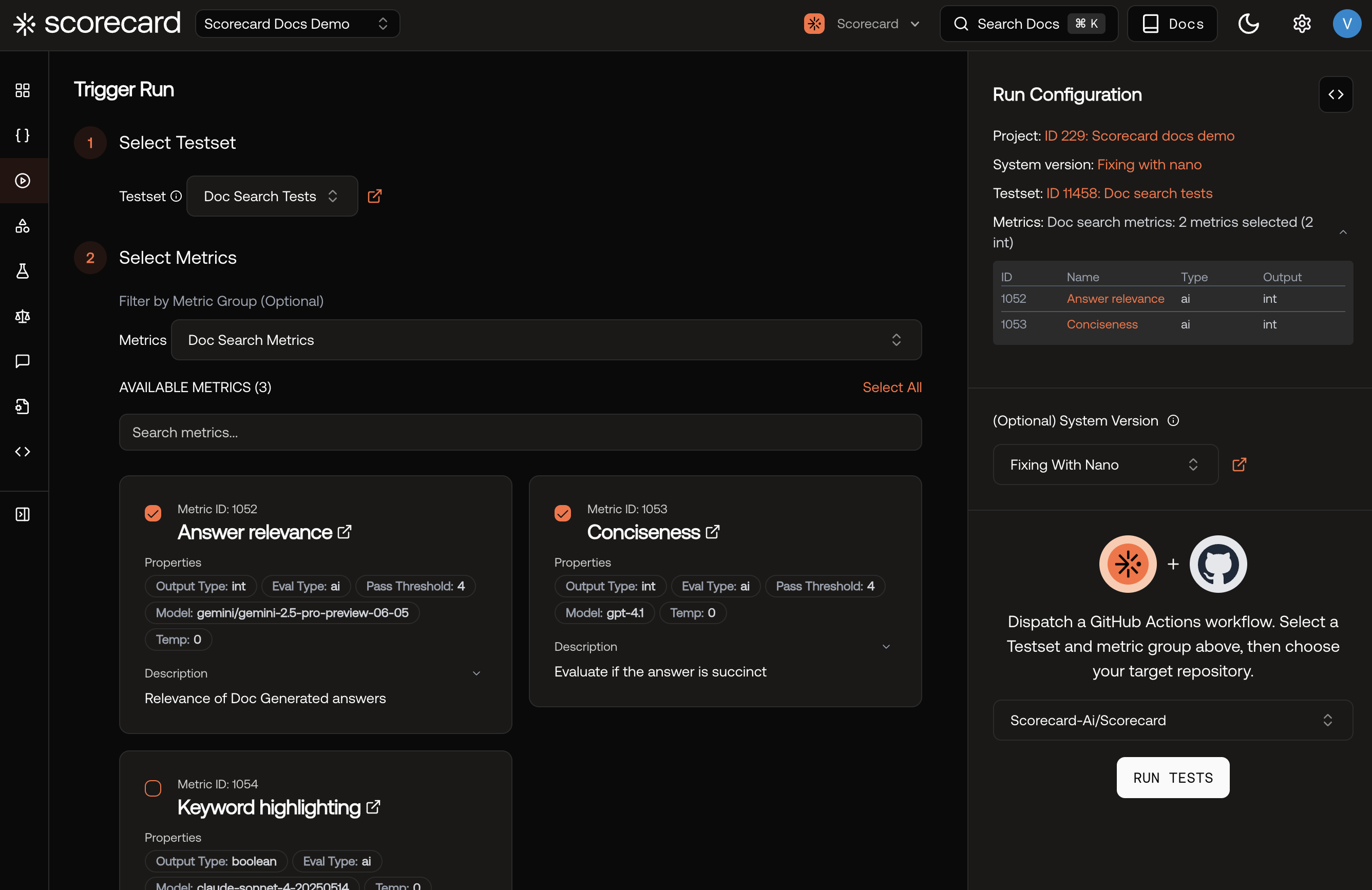
To operationalize RAG quality on live traffic, instrument traces (Tracing Quickstart). Scorecard will sample spans, extract prompts/completions, and create Runs automatically.