Overview
Scorecard’s MCP (Model Context Protocol) server lets you manage projects, create testsets, configure metrics, run evaluations, and analyze results through natural language in any MCP-compatible client.Available Tools
The MCP server has ~45 tools covering projects, testsets, testcases, systems, metrics, runs, records, scores, and annotations, plus documentation search. Each tool maps to a Scorecard API operation, so anything the SDK can do is available in natural language. The full tool reference is at the bottom of this page.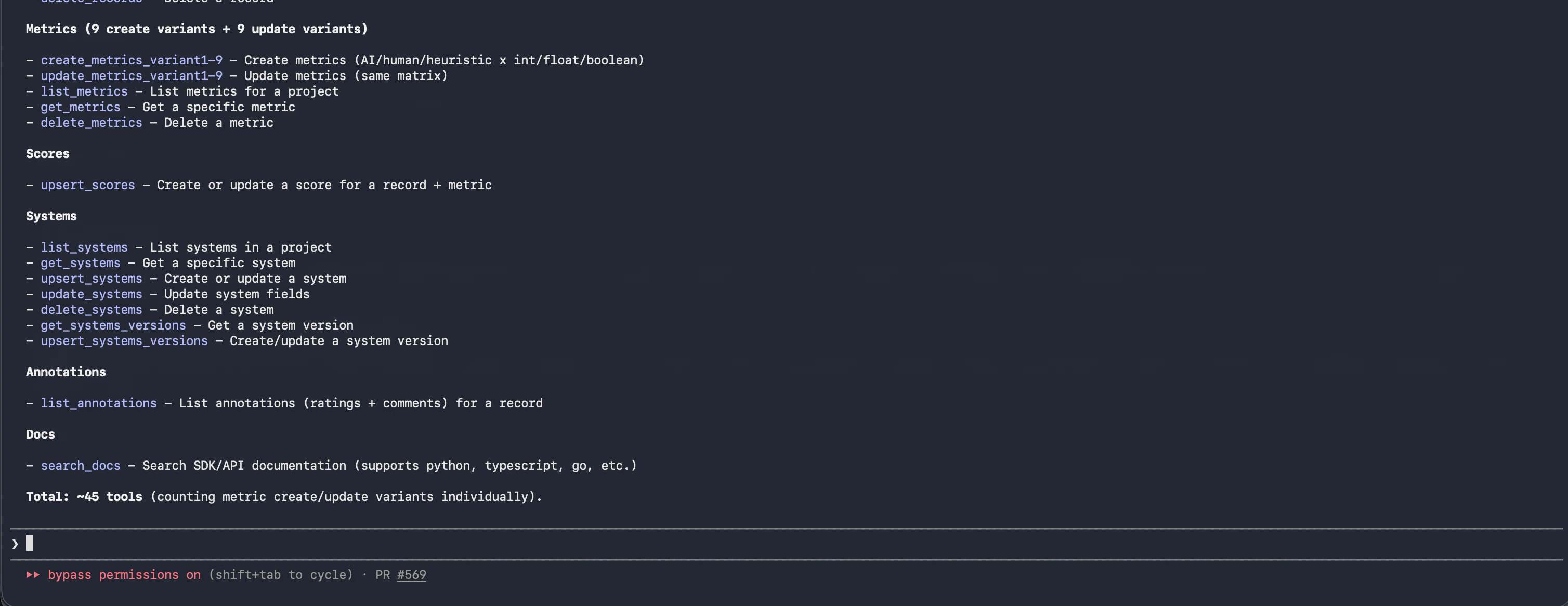
Scorecard MCP server tools listed in Claude Code.
Setting Up the MCP Server
Claude Code
Add the Scorecard remote MCP server with a single command:scorecard: https://mcp.scorecard.io/mcp (HTTP) - ✓ Connected.
Claude Desktop
Go to Claude Desktop settings and click the “Connectors” tab. Click “Add custom connector” and paste the URL:https://mcp.scorecard.io/mcp. Click “Add”, then “Connect” to login to Scorecard.
Local configuration
You can run the MCP server locally via npx:Examples
Create a project and testset
Create metrics
Analyze results
Review human feedback
Generate testcases from a codebase
In Claude Code, you can combine file access with the MCP server:Iterate on metrics
Technical Details
- Built on the Model Context Protocol standard
- Compatible with any MCP client (Claude Code, Claude Desktop, Cursor, and more)
- Secured with OAuth authentication
- Open source: github.com/scorecard-ai/scorecard-mcp
Tool reference
Projects
Projects
Testsets
Testsets
Testcases
Testcases
Systems
Systems
Metrics
Metrics
The server splits
create_metrics and update_metrics into one variant per metric type, so the structure of the call depends on the metric’s evalType (ai, human, or heuristic) and outputType (integer or boolean). Your client picks the right variant automatically based on the metric you describe.Runs
Runs
Records and scores
Records and scores
Annotations
Annotations
Documentation
Documentation