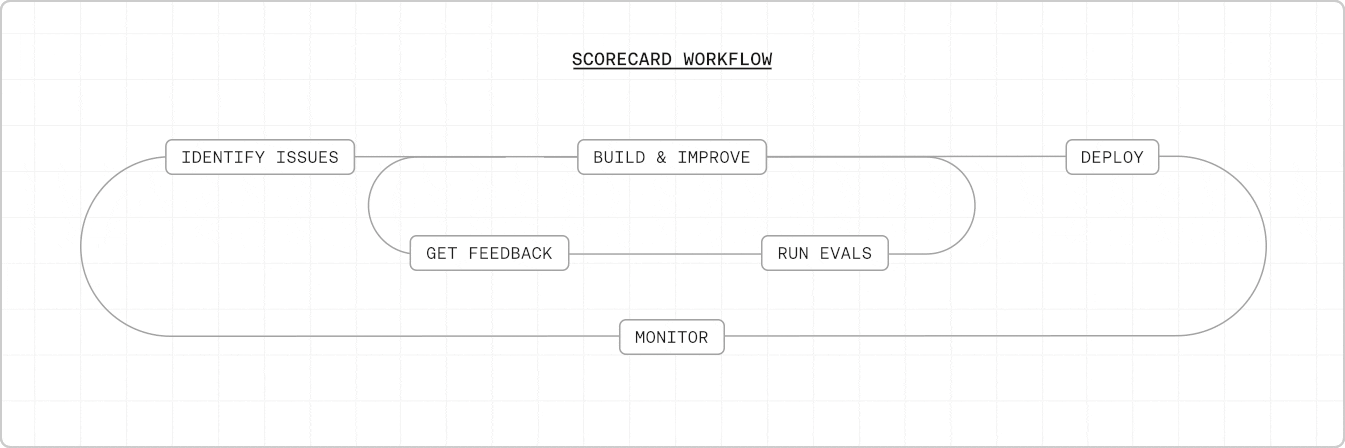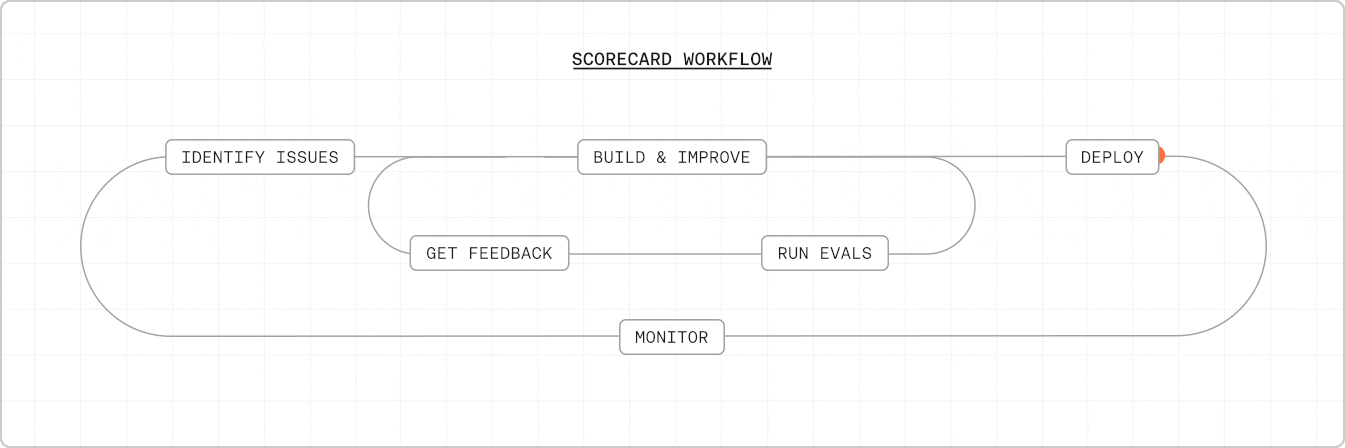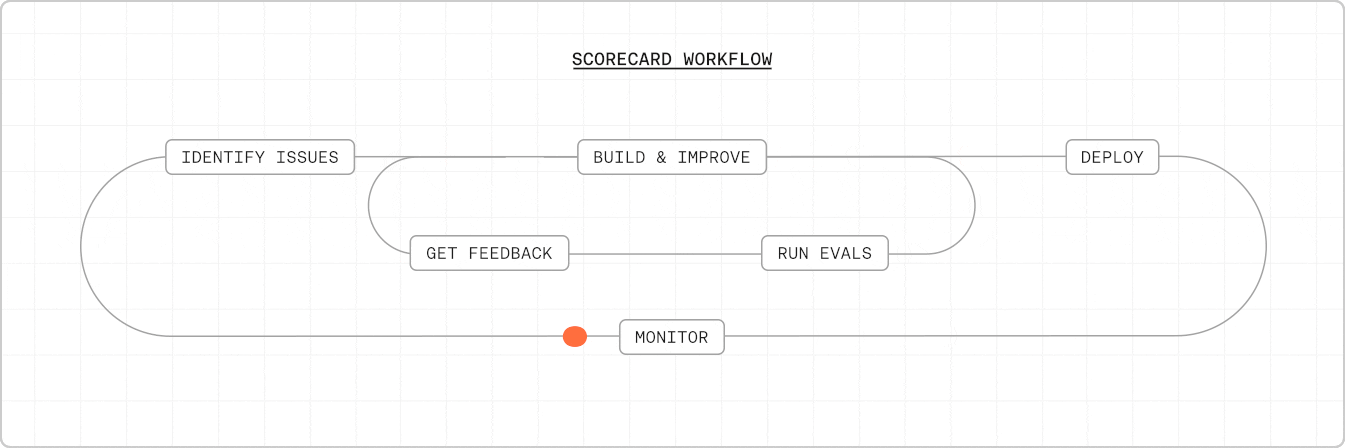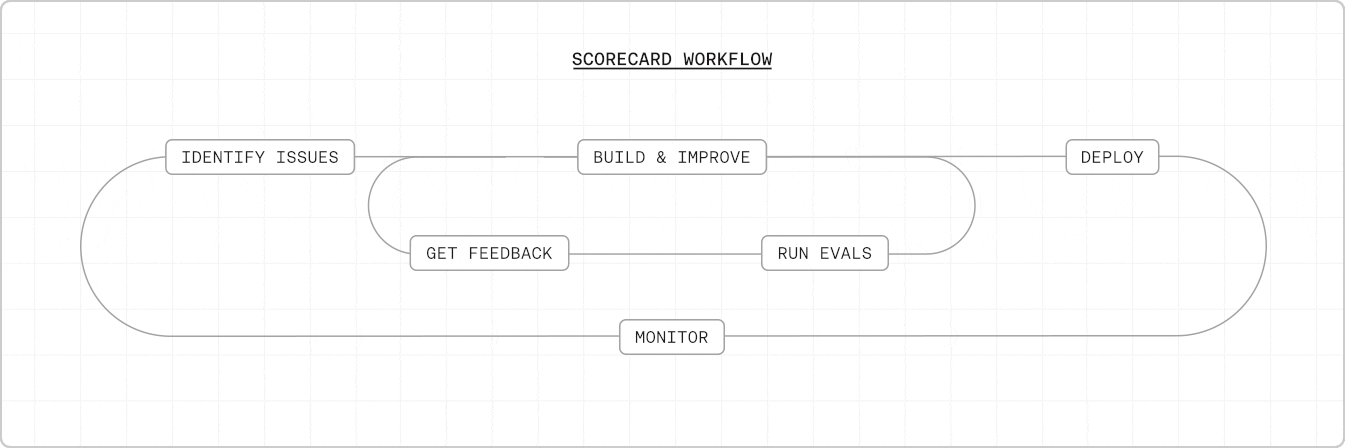
The bottleneck is feedback, not building
Teams are building increasingly complex agents — multi-step workflows, consequential actions, real-world integrations. But the way most teams validate these agents hasn’t kept up. The current approach is manual: review a handful of production cases, wait weeks for expert feedback, and hope nothing slips through. This limits you to scenarios you’ve already seen. Edge cases stay hidden until they hit production. Expert time doesn’t scale — every new capability means more review cycles, longer iteration loops, and slower releases. The bottleneck has shifted from building to feedback. Scorecard flips this by turning expert judgment into automated reward models and replacing manual review with large-scale simulation.How Scorecard works
Encode expert judgment
Define reward criteria in natural language. Scorecard turns them into automated judges that score every scenario consistently and at scale.Learn about metrics →
Simulate at scale
Run your agent through thousands of realistic scenarios using AI-powered personas. Generate diverse test scenarios automatically — no manual case writing required.Multi-turn simulation → · Synthetic data generation →
Compare and improve
Quantitative A/B comparison across every metric. Iterate visually in the Playground with real-time feedback to find the best prompt, model, or architecture.A/B comparison → · Playground →
Ship with confidence
Integrate simulation into CI/CD so every pull request is validated automatically. Monitor production with tracing and feed real traffic back into your simulation suite.GitHub Actions → · Tracing →
Works with your agent stack
Claude Agent SDK
Zero-code tracing. Set three environment variables and get full visibility into agent decisions, tool use, and costs.
LangChain
Trace LangChain agents and chains with OpenTelemetry.
Any LLM
Works with OpenAI, Anthropic, Google, and any OpenTelemetry-compatible provider.
Get started
Built by engineers from Waymo, Uber, and SpaceX who used large-scale simulation to ship autonomous vehicles, global logistics, and rockets — now applied to AI agents.Run your first evaluation
Set up Scorecard and run a simulation in minutes.
Try the Playground
Start testing without writing code.
Talk to our team
Book a demo and see Scorecard in action.