Integrate guardrails with Scorecard
Use Scorecard to track how often guardrails trigger and whether conversations comply with your policies.- Create a boolean, heuristic Metric (e.g., “PII blocked”).
- When a rail triggers, send a boolean Score for the current interaction.
Minimal example (SDK)
Below, assume you already created a Metric withevalType = heuristic and outputType = boolean in your Project, and you have a RUN_ID for grouping related interactions. When your guardrail fires (in NeMo Guardrails or Guardrails AI), create a Record for the event and upsert a boolean Score.
- Create the guardrail Metric once per Project (e.g., “PII blocked”). Use it across systems and environments.
- Attach additional attributes to your Records (e.g., model name, environment) so you can slice in Scorecard.
- If you already created a Record for the same interaction, reuse that
record.idand only callscores.upsert. AScoreis uniquely keyed by(recordId, metricConfigId)and is safe to upsert repeatedly. - Prefer one
Testrecordper interaction and multiple Metrics/Scores per record (one per guardrail), instead of creating multiple records for the same interaction.
How it works under the hood
- A
Rungroups manyTestrecords(each interaction you log creates one record). - For each
Testrecord, you can have multipleScores— one per Metric attached to the Run. - For AI Metrics, Scorecard enqueues background scoring jobs that generate
Scoresautomatically. - For heuristic/guardrail checks, you can directly upsert a
Scoreyourself, like in the example above. - Boolean metrics should use
{ binaryScore: true|false, reasoning: string }; integer metrics should use{ intScore: number, reasoning: string }so pass/fail and aggregations work out of the box.
Benefits of Using AI Guardrails
Key benefits of adding programmable guardrails include:- Trustworthiness and Reliability: Guardrails can be used to guide and safeguard conversations between your users and your LLM system. You can choose to define the behavior of your LLM system on specific topics and prevent it from engaging in discussions on unwanted topics.
- Controllable Dialog: Use guardrails to steer the LLM to follow pre-defined conversational flows, making sure the LLM follows best practices in conversation design and enforces standard procedures, such as authentication.
- Protection against Vulnerabilities: Guardrails can be specified in a way that they can help increase the security of your LLM application by checking for LLM vulnerabilities, such as checking for secrets in user inputs or LLM responses or detecting prompt injections.
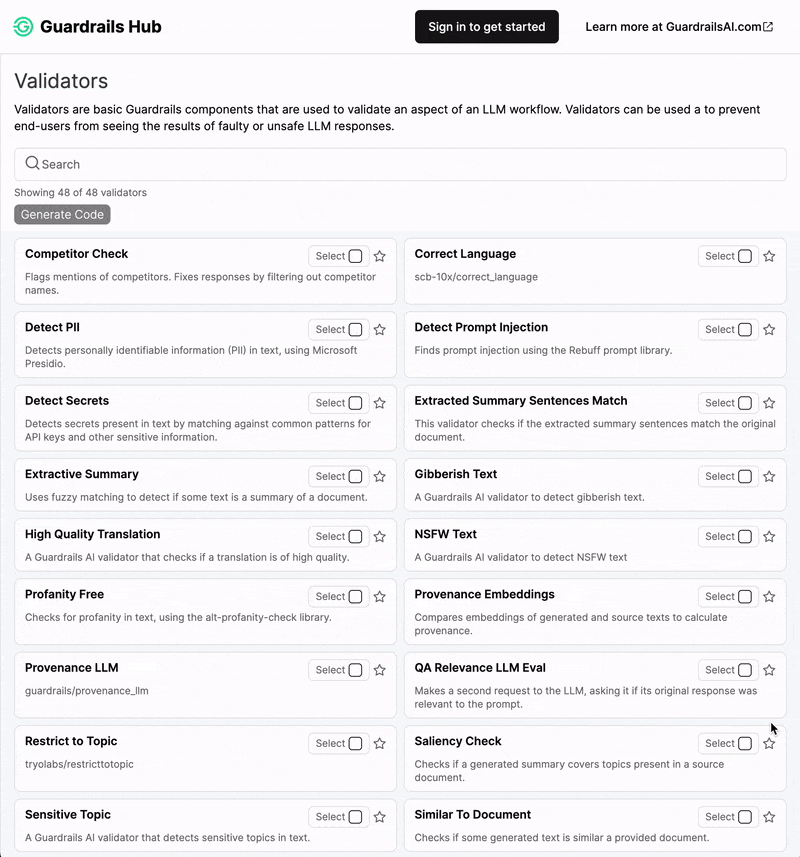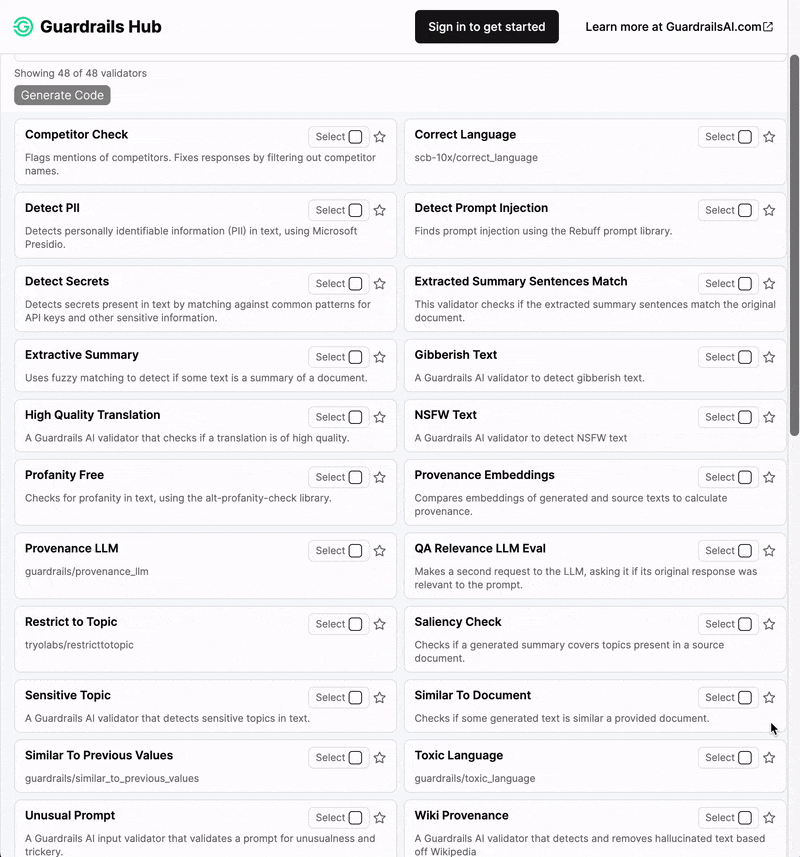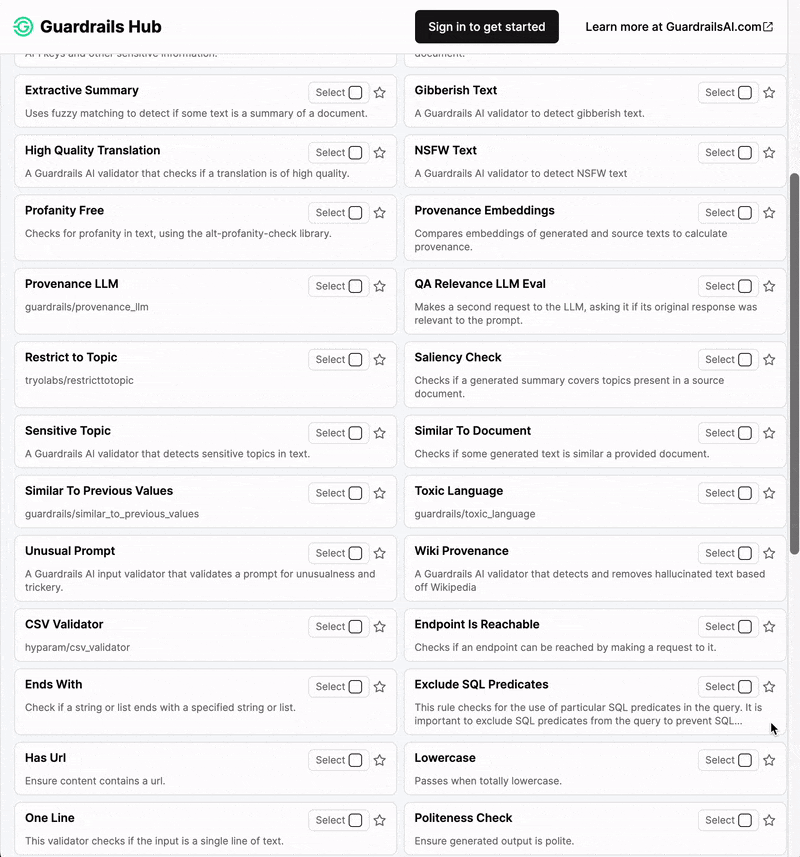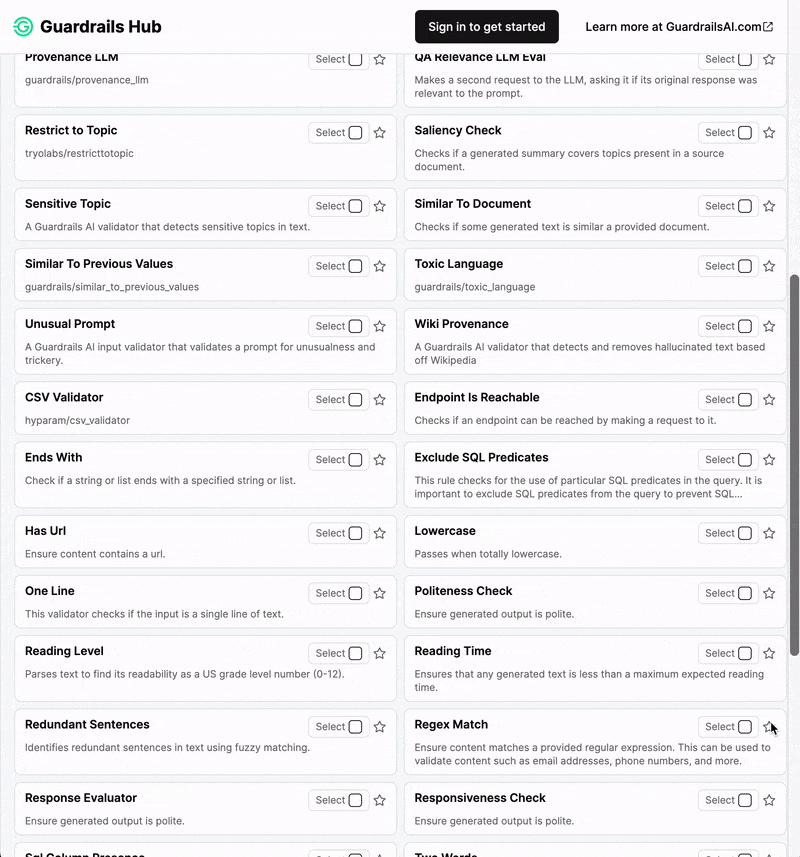
Types of Guardrails
In the following, we give a brief overview of the types of guardrails that can be specified with the open-source toolkits NeMo Guardrails and Guardrails AI. For further technical documentation, please check out the respective GitHub repositories and documentations.NeMo Guardrails
- Technical Documentation: https://docs.nvidia.com/nemo/guardrails
- GitHub Repository: https://github.com/NVIDIA/NeMo-Guardrails
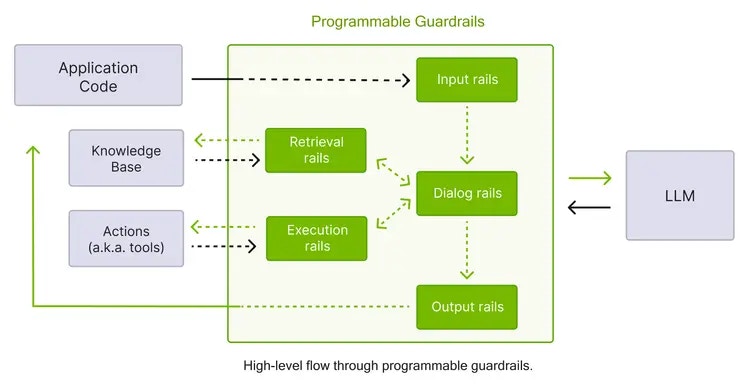
- Input Rails: Checking the user input, an input rail can reject, change (e.g., to rephrase or mask sensitive data), or stop processing the input.
- Dialog Rails: Dialog rails influence how the LLM is prompted and determine if an action should be executed, if the LLM should be invoked to generate the next step or a response, if a predefined response should be used instead, etc.
- Retrieval Rails: When using a RAG (Retrieval Augmented Generation) LLM system, retrieval rails check the retrieved documents and can reject, change (e.g., to rephrase or mask sensitive data), or stop processing specific chunks.
- Execution Rails: Execution rails use mechanisms to check and verify the inputs and/or outputs of custom actions that are being evoked by the LLM (e.g., the LLM triggering actions in other tools).
- Output Rails: Checking the response of a LLM, an output rail can reject, change (e.g., remove sensitive data), or remove a LLM’s response.
Guardrails AI
- Technical Documentation: https://www.guardrailsai.com/docs
- GitHub Repository: https://github.com/guardrails-ai/guardrails