Build testsets and metrics conversationally with Claude Desktop and the Scorecard MCP server
Use the Scorecard MCP (Model Context Protocol) server to create evaluation testsets and metrics through natural language in Claude. Instead of writing code or clicking through UIs, just tell Claude what you need and it will use the Scorecard API to set everything up.
This quickstart uses Claude Desktop, but it also works with other MCP clients, like Cursor and Claude Code.
Open Claude and add the Scorecard MCP server using the remote configuration:
Open Claude settings
Navigate to the “MCP Servers” section
Add a new remote server with URL: https://mcp.scorecard.io/mcp
Complete the OAuth authentication flow to connect your Scorecard account
The remote MCP server requires no local dependencies or API key management. Authentication happens securely through your browser.
Once connected, Claude will have access to all Scorecard API capabilities through natural language.
3
Create a project
Simply ask Claude to create a new Scorecard project:
Create a new Scorecard project called “Customer Support Bot Evaluation” for testing my AI customer support assistant.
Screenshot of the conversation showing project creation in Claude
Claude will automatically use the appropriate MCP tools (like create_projects, list_projects) based on your natural language request.
4
Create a testset with testcases
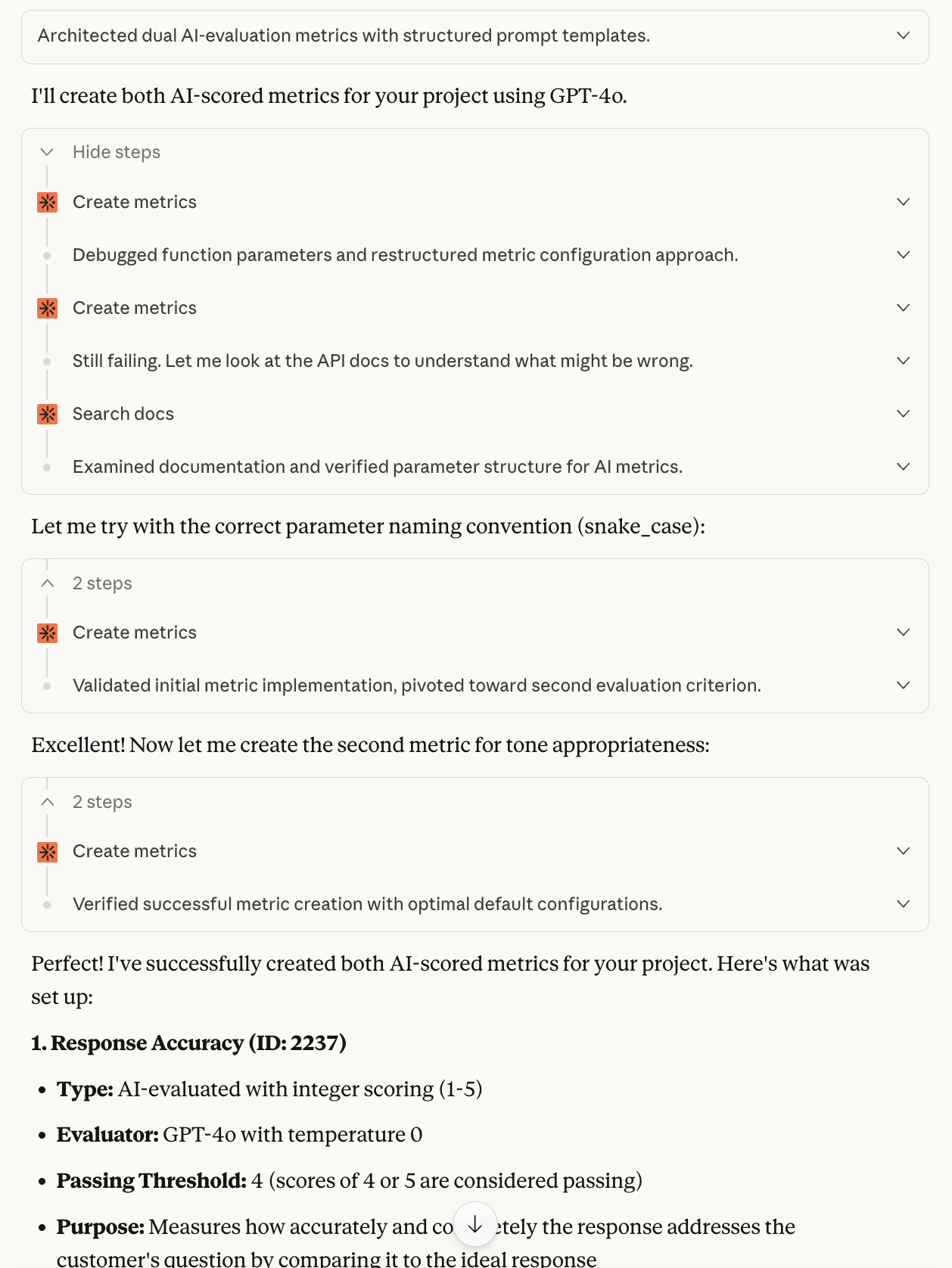
Now create a testset to hold your evaluation test cases. Describe the structure you need:
Create a testset called “Support Scenarios” in this project. The testcases should have:
Input fields: “customerMessage” (the customer’s question) and “category” (support category like billing, technical, or product)
Expected output field: “idealResponse” (what a great response from the agent looks like)
Metadata field: “difficulty” (easy, medium, or hard)
Then add 5 testcases covering different support scenarios.
Screenshot of the conversation showing testset creation in Claude
Claude can usually guess which inputs and output fields you want, but it’s better to tell it what your field names are.
5
Create evaluation metrics
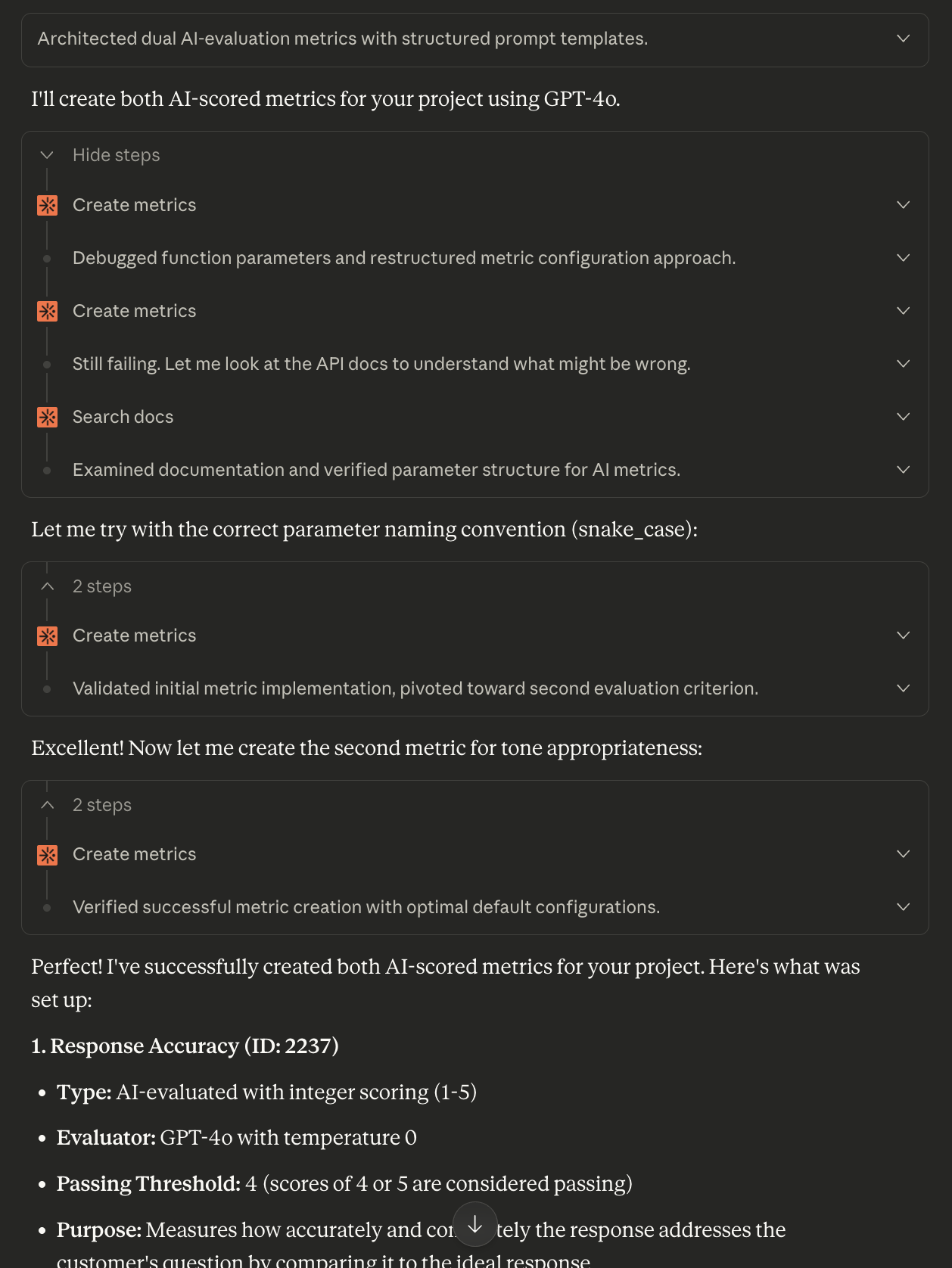
Define metrics to evaluate your AI system. Describe what “good” looks like:
Create two AI-scored metrics for this project:
“Response Accuracy” (integer) - Measures how well the response answers the customer’s question compared to the ideal response
“Tone Appropriateness” (boolean) - Checks if the response uses professional, empathetic language appropriate for customer support
Use GPT-4o as the evaluator with temperature 0 for consistency.
Screenshot of the conversation showing metric creation in Claude
Claude’s initial tool call to create_metrics failed because it used the wrong arguments, but it was able to eventually succeed by reading the documentation and trying again.
6
View your setup in Scorecard
Open your Scorecard project in the web UI to see everything that was created!Everything is now ready to score records. You can score records against your metrics through the UI, SDK, or continue using Claude with MCP.
7
Next: Score records
You can score records from the Records page, the SDK, or the Scorecard playground.You can also continue the conversation to analyze and iterate on your metrics and scores.
Explain the latest scoring results for this project.
Update the Response Accuracy metric to be stricter about factual details.
Add 5 more testcases covering edge cases like angry customers and off-topic questions.
The MCP server gives Claude access to the full Scorecard API, so you can manage your entire evaluation workflow conversationally.
Be specific about data structures: When creating testsets, clearly describe the field names, types, and which fields are inputs vs expected outputs. This helps Claude set up the schema correctly.
Describe evaluation criteria: When creating metrics, explain what makes a “good” output in detail. Claude will translate this into effective evaluation guidelines.
Ask for recommendations: Claude can suggest metrics, testcase scenarios, and evaluation strategies based on your use case. Just ask “What metrics should I use for evaluating a RAG system?”
Iterate conversationally: Made a mistake? Just ask Claude to fix it: “Update that metric to use temperature 0.1 instead” or “Add a new field called ‘priority’ to the testset”
The Scorecard MCP server works with most MCP clients, including Claude Desktop, Cursor, and Claude Code. Make sure you’ve added the remote server URL correctly (https://mcp.scorecard.io/mcp) and completed the OAuth flow. See the MCP Server documentation for more installation instructions.
MCP server does not show up in Claude.
Make sure you’ve added the remote server URL correctly (https://mcp.scorecard.io/mcp) and completed the OAuth flow. Restart Claude if needed.
Claude shows an authentication error.
The MCP server uses OAuth tokens that may expire. Try disconnecting and reconnecting the MCP server in Claude settings to refresh authentication.
Claude says it can't find MCP tools.
Verify the MCP server is connected and enabled in Claude settings. You should see “Scorecard” listed in your active MCP servers.
I can't connect to remote MCP servers.
For local installation with your Scorecard API key, see the MCP Server documentation. Use npx -y scorecard-ai-mcp@latest with environment variables.